一、协程
1、协程
阻塞:代码执行到会产生阻塞操作的地方(如IO,socket.recv()等)会等待操作完成才继续往下执行。
非阻塞:即执行到阻塞操作时不会等待,而是将IO类操作交给其他程序或系统内核进程,然后会继续往下执行,等待系统返回完成信号,直接处理结果。
协程是阻塞模式
协程可以在单线程下实现高并发效果,在遇到IO时可以进行切换,然后执行其他任务,IO操作完成后再切换回来。协程本质上还是单线程,需要在进程的配合下才能理用多CPU。
协程在IO操作的时候时阻塞模式,即在某个方法内出现IO操作时就被阻塞,不能继续往下执行,IO完成后再继续往下执行,效果和生成器一样,但对于整个线程来说可以实现在多个方法或代码之前来回切换。
协程定义:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 一个协程遇到IO操作自动切换到其它协程
python">import time
def consumer(name):
print("{name} starting eating baozi".format(name=name))
while True:
new_baozi = yield # 等待producer制作包子
time.sleep(1)
print("{name} eating baozi {noew_baozi}".format(name=name, noew_baozi=new_baozi))
def producer(*args):
for con in args:
next(con) # 先next一次,让consumer执行到new_baozi = yield处
n = 0
while n < 3:
n += 1
print("the {n} time making a baozi".format(n=n))
for con in args:
con.send(n) # 手动切换到consumer函数,并返回new_baozi的值
if __name__ == '__main__':
con1 = consumer("c1")
con2 = consumer("c2")
con3 = consumer("c3")
producer(con1, con2, con3)
"""
输出:
c1 starting eating baozi
c2 starting eating baozi
c3 starting eating baozi
the 1 time making a baozi
c1 eating baozi 1
c2 eating baozi 1
c3 eating baozi 1
the 2 time making a baozi
c1 eating baozi 2
c2 eating baozi 2
c3 eating baozi 2
the 3 time making a baozi
c1 eating baozi 3
c2 eating baozi 3
c3 eating baozi 3
"""
2、Gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
python">from gevent import monkey # 自动识别那些模块会产生IO操作,然后自动进行切换
from urllib.request import urlopen
import gevent
monkey.patch_all() # 加载所有默认的补丁,识别那些事阻塞操作
def func(url):
print("get :{url} ".format(url=url))
response = urlopen(url)
data = response.read()
print("{data_len} bytes received from {url}".format(data_len=len(data), url=url))
url_list = ["http://baidu.com", "http://taobao.com", "http://jd.com", "http://douyu.com"]
print("同步模式")
for i in url_list:
func(i)
print("异步模式")
gevent.joinall([gevent.spawn(func, url) for url in url_list]) # [gevent.spawn(func, url) for url in url_list] 列表生成式
# gevent.joinall([]) # 这个函数可以使list里面的函数遇到io操作会主动进行切换,否则就需要等待io操作完成
"""
输出:
同步模式
get :http://baidu.com
118442 bytes received from http://baidu.com
get :http://taobao.com
144945 bytes received from http://taobao.com
get :http://jd.com
108724 bytes received from http://jd.com
get :http://douyu.com
94158 bytes received from http://douyu.com
异步模式
get :http://baidu.com
get :http://taobao.com
get :http://jd.com
get :http://douyu.com
118442 bytes received from http://baidu.com
94158 bytes received from http://douyu.com
108724 bytes received from http://jd.com
144945 bytes received from http://taobao.com
""" 上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在list中,此list被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走
3、单线程socket并发
python">from gevent import socket, monkey, spawn
monkey.patch_all() # 识别那些是阻塞操作
def server(port):
s = socket.socket()
s.bind(("0.0.0.0", port))
s.listen(500)
while True:
conn, addr = s.accept() # 在这里阻塞,有新消息的时候会返回conn.recv
print(addr)
spawn(handle_request, conn) # 交给协程处理
def handle_request(conn):
try:
while True:
data = conn.recv(1024) # 在这里阻塞,有新连接来的时候会回到s.accept
send_msg = "recv:" + data.decode("utf8")
conn.send(send_msg.encode("utf8"))
if not data:
conn.shutdown(socket.SHUT_WR)
except Exception as e:
print(e)
finally:
conn.close()
if __name__ == '__main__':
server(8888)
python">import socket
import threading
import time
from multiprocessing import Process
def client(pid):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("localhost", 8888))
while True:
time.sleep(1)
# msg = input(">>").encode("utf8")
msg = str(pid).encode("utf8")
s.sendall(msg)
data = s.recv(1024)
print(data.decode("utf8"))
if __name__ == '__main__':
client_list = []
for i in range(1000):
t = threading.Thread(target=client, args=(i,)) # 内存29% CPU24%
# t = Process(target=client, args=(i,)) # 内存100% CPU100%
t.start()
client_list.append(t)
for client in client_list:
client.join()
二、事件驱动与IO模型
IO模式
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
同步synchronous:
1、阻塞 I/O(blocking IO)
2、非阻塞 I/O(nonblocking IO)
3、I/O 多路复用( IO multiplexing)
4、信号驱动 I/O( signal driven IO)
异步asynchronous:
5、异步 I/O(asynchronous IO)
注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
1、阻塞IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
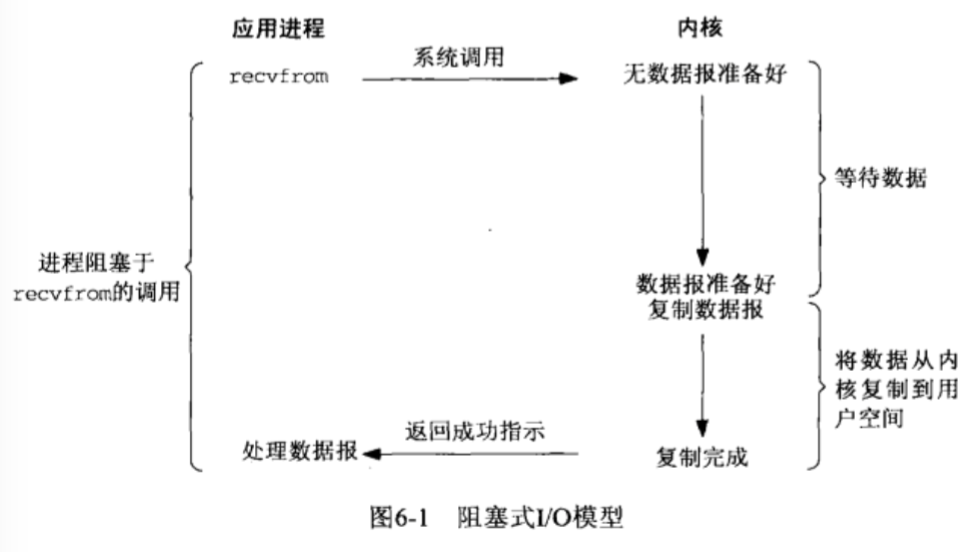
内核将数据从源文件拷贝到缓存,和缓存中copy到进程中都是阻塞的。
- 优点:能够及时返回数据,无延迟;方便调试;
- 缺点:需要付出等待的代价;
2、非阻塞IO
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
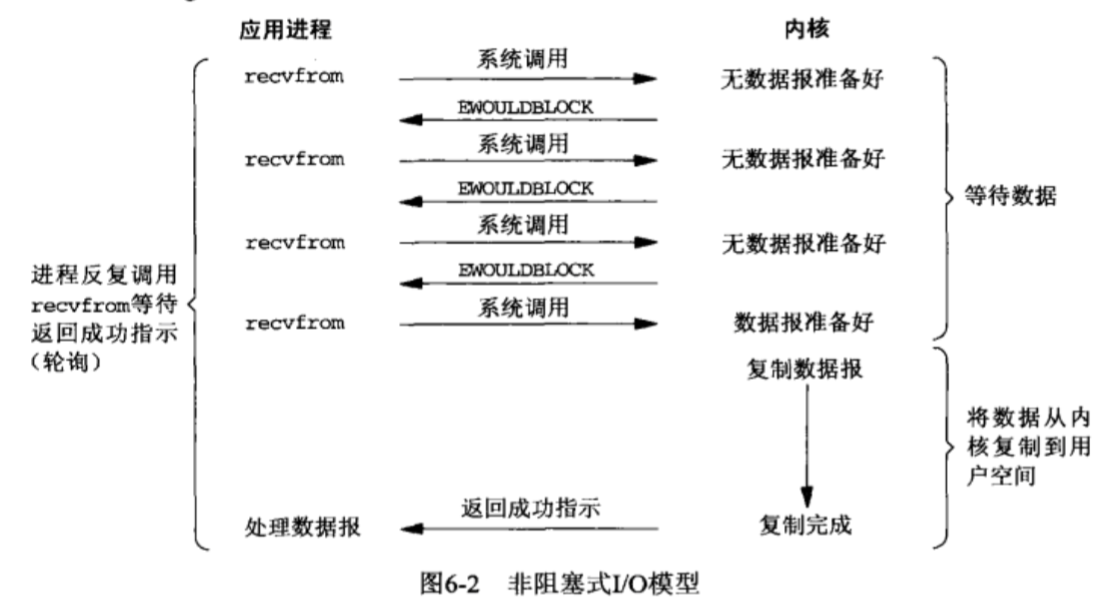
从图中可以得知,前三次系统调用时都没有数据可以返回,内核均返回一个 EWOULDBLOCK,并且不会阻塞当前进程,直到第四次询问内核缓冲区是否有数据的时候,此时内核缓冲区中已经有一个准备好的数据,因此将内核数据复制到用户空间,此时系统调用则返回成功;
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
-
优点:相较于阻塞模型,非阻塞不用再等待任务,而是把时间花费到其它任务上,也就是这个当前线程同时处理多个任务;
-
缺点:导致任务完成的响应延迟增大了,因为每隔一段时间才去执行询问的动作,但是任务可能在两个询问动作的时间间隔内完成,这会导致整体数据吞吐量的降低。
3、多路复用IO
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程
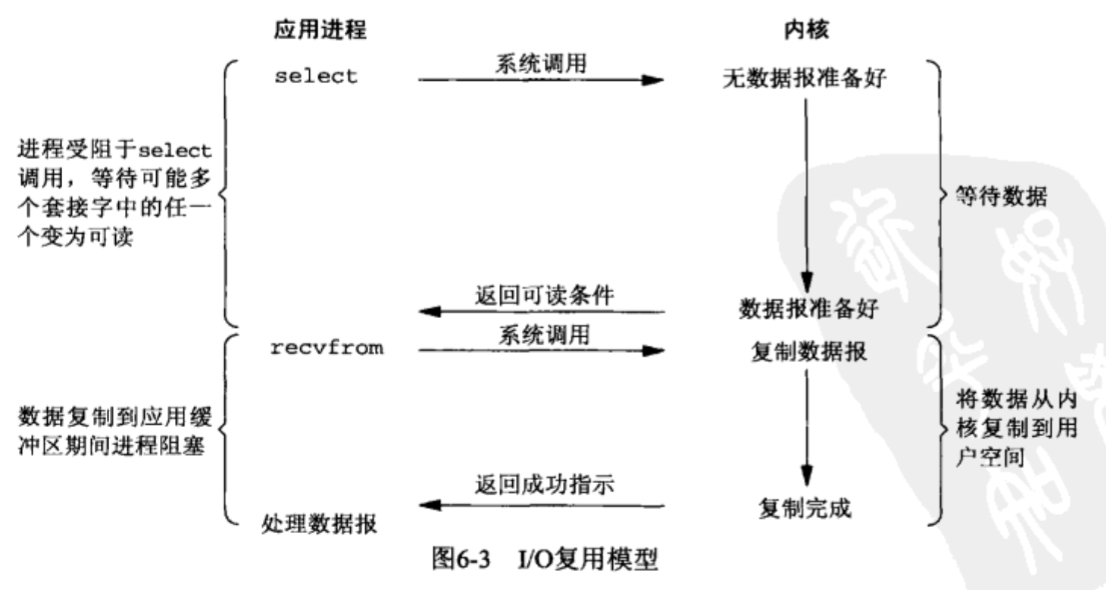
图中阻塞于 select 调用,等待数据报套接字变为可读。当select返回套接字可读这一条件的时候,则调用 recvfrom 把所读数据报复制到应用进程缓冲区;
与之前的同步非阻塞方式需要用户进程不停的轮询不同,IO多路复用不需要不停的轮询,而是派别人去帮忙循环查询多个任务的完成状态,UNIX/Linux 下的 select、poll、epoll 就是干这个的;select调用是内核级别的,select轮询相对非阻塞的轮询的区别在于---前者可以等待多个socket,能实现同时对多个IO端口进行监听,当其中任何一个socket的数据准好了,就能返回进行可读,然后进程再进行recvform系统调用,将数据由内核拷贝到用户进程,当然这个过程是阻塞的。select或poll调用之后,会阻塞进程,与blocking IO阻塞不同在于,此时的select不是等到socket数据全部到达再处理, 而是有了一部分数据(网络上的数据是分组到达的)就会调用用户进程来处理。如何知道有一部分数据到达了呢?监视的事情交给了内核,内核负责数据到达的处理。
我认为上面那句话中存在两个重要点:1.对多个socket进行监听,只要任何一个socket数据准备好就返回可读;2.不等一个socket数据全部到达再处理,而是一部分socket的数据到达了就通知用户进程;
其实 select、poll、epoll 的原理就是不断的遍历所负责的所有的socket完成状态,当某个socket有数据到达了,就返回可读并通知用户进程来处理;
- 优点:能够同时处理多个连接,系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程的运行,降低了系统的维护工作量,节省了系统资源。
- 缺点:如果处理的连结数目不高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。(因为阻塞可以保证没有延迟,但是多路复用是处理先存在的数据,所以数据的顺序则不管,导致处理一个完整的任务的时间上有延迟)
4、信号驱动模式

首先开启套接字的信号驱动式IO功能,并且通过 sigaction 系统调用安装一个信号处理函数,该函数调用将立即返回,当前进程没有被阻塞,继续工作;当数据报准备好的时候,内核则为该进程产生 SIGIO 的信号,随后既可以在信号处理函数中调用 recvfrom 读取数据报,并且通知主循环数据已经准备好等待处理,也可以通知主循环让它读取数据报;(其实就是一个待读取的通知和待处理的通知);
5、异步
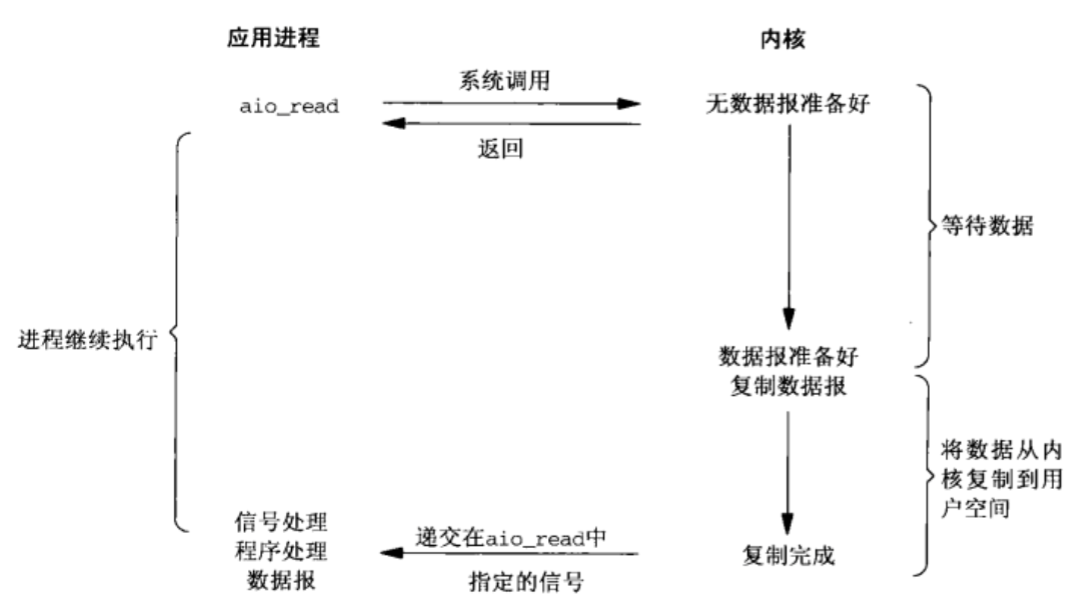
调用 aio_read 函数,给内核传递描述符、缓冲区指针、缓冲区大小和文件偏移,并且告诉内核当整个操作完成时如何通知我们。该函数调用后立即返回,不被阻塞;
6、五种IO模式比较
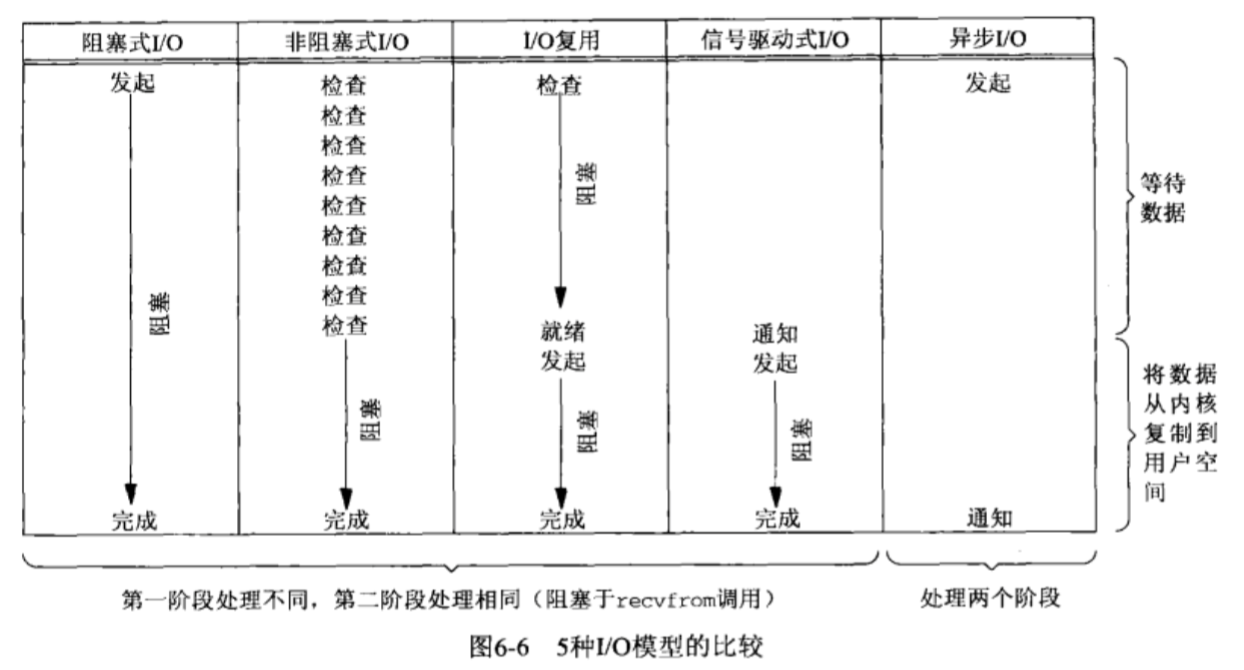
7、Select、Poll、Epoll
select
select 是通过系统调用来监视着一个由多个文件描述符(file descriptor)组成的数组,当select()返回后,数组中就绪的文件描述符会被内核修改标记位(其实就是一个整数),使得进程可以获得这些文件描述符从而进行后续的读写操作。select饰通过遍历来监视整个数组的,而且每次遍历都是线性的。
优点:
select目前几乎在所有的平台上支持,良好跨平台性。
缺点
- 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多的时候会很大
- 单个进程能够监视的fd数量存在最大限制,在linux上默认为1024(可以通过修改宏定义或者重新编译内核的方式提升这个限制)
- 并且由于select的fd是放在数组中,并且每次都要线性遍历整个数组,当fd很多的时候,开销也很大
select多并发socket例子
python">import queue
import socket
import select
server = socket.socket()
server.setblocking(False)
server.bind(("0.0.0.0", 8888))
print("server starting listen")
server.listen(10)
inputs = [server]
outputs = []
conn_dict = {}
while True:
readable, writeable, exceptional = select.select(inputs, outputs, inputs)
# 参数1:检测文件描述符fd,如果就绪就放到里面, 对应readable,活动的fd
# 参数2:下次循环就输出里面的参数不会检测 对应writeable,outputs == writeable
# 参数3:检测所有的fd,如果断开或者异常就返回 对应exceptional,如果有异常的就返回到exceptional
for r in readable:
if r is server: # inputs里面既有server,也有conn,需要判断
conn, addr = server.accept()
conn_dict[conn] = queue.Queue() # 建立链接,同时在字典里面创建一个队列存放消息
inputs.append(conn) # 把链接放入input进行检测
else:
try:
data = r.recv(1024)
except ConnectionResetError as e: # 主机中途断开异常
continue
send_msg = data.decode("utf8").upper().encode("utf8")
conn_dict[r].put(send_msg) # 为了验证outputs,这里不直接发送,等待writeable一起发送
if r not in outputs:
outputs.append(r)
print(data.decode("utf8"))
for conn in writeable: # outputs里面的conn
try:
send_msg = conn_dict[conn].get_nowait() # 根据conn取到上一步放入的消息,同时不阻塞
except queue.Empty as e:
print("queue is empty") # 如果异常就说明里面没有消息
outputs.remove(conn)
else:
conn.send(send_msg)
print("send msg done")
for conn in exceptional: # exceptional里面存放的是异常的链接
inputs.remove(conn)
if conn in outputs:
outputs.remove(conn)
del conn_dict[conn]
conn.close()
python">import socket
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(("localhost", 8888))
while True:
msg = input(">>").encode("utf8")
client.send(msg)
data = client.recv(1024)
print(data.decode("utf8"))
Poll
poll本质上和select没有区别,只是没有了最大连接数(linux上默认1024个)的限制,原因是它基于链表存储的。
python">#!/usr/bin/env python
# -*- coding: utf-8 -*-
import select, socket
response = b"hello world"
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serversocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serversocket.bind(('192.168.199.197', 8080))
serversocket.listen(1)
serversocket.setblocking(0)
#
poll = select.poll()
poll.register(serversocket.fileno(), select.POLLIN)
connections = {}
while True:
for fd, event in poll.poll():
if event == select.POLLIN:
if fd == serversocket.fileno():
con, addr = serversocket.accept()
poll.register(con.fileno(), select.POLLIN)
connections[con.fileno()] = con
else:
con = connections[fd]
data = con.recv(1024)
if data:
poll.modify(con.fileno(), select.POLLOUT)
elif event == select.POLLOUT:
con = connections[fd]
con.send(response)
poll.unregister(con.fileno())
con.close()
Epoll
在linux2.6(准确来说是2.5.44)由内核直接支持的方法。epoll解决了select和poll的缺点。
- 对于第一个缺点,epoll的解决方法是每次注册新的事件到epoll中,会把所有的fd拷贝进内核,而不是在等待的时候重复拷贝,保证了每个fd在整个过程中只会拷贝1次。
- 对于第二个缺点,epoll没有这个限制,它所支持的fd上限是最大可以打开文件的数目,具体数目可以cat /proc/sys/fs/file-max查看,一般来说这个数目和系统内存关系比较大。
- 对于第三个缺点,epoll的解决方法不像select和poll每次对所有fd进行遍历轮询所有fd集合,而是在注册新的事件时,为每个fd指定一个回调函数,当设备就绪的时候,调用这个回调函数,这个回调函数就会把就绪的fd加入一个就绪表中。(所以epoll实际只需要遍历就绪表)。
epoll同时支持水平触发和边缘触发:
- 水平触发(level-triggered):只要满足条件,就触发一个事件(只要有数据没有被获取,内核就不断通知你)。e.g:在水平触发模式下,重复调用
epoll.poll()会重复通知关注的event,直到与该event有关的所有数据都已被处理。(select, poll是水平触发, epoll默认水平触发) - 边缘触发(edge-triggered):每当状态变化时,触发一个事件。e.g:在边沿触发模式中,epoll.poll()在读或者写event在socket上面发生后,将只会返回一次event。调用
epoll.poll()的程序必须处理所有和这个event相关的数据,随后的epoll.poll()调用不会再有这个event的通知。
python">import socket, select
EOL1 = b'\n\n'
EOL2 = b'\n\r\n'
response = b'HTTP/1.0 200 OK\r\nDate: Mon, 1 Jan 1996 01:01:01 GMT\r\n'
response += b'Content-Type: text/plain\r\nContent-Length: 13\r\n\r\n'
response += b'Hello, world!'
serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serversocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serversocket.bind(('0.0.0.0', 8080))
serversocket.listen(1)
serversocket.setblocking(0)
epoll = select.epoll()
epoll.register(serversocket.fileno(), select.EPOLLIN)
try:
connections = {}; requests = {}; responses = {}
while True:
events = epoll.poll(1)
for fileno, event in events:
if fileno == serversocket.fileno():
connection, address = serversocket.accept()
connection.setblocking(0)
epoll.register(connection.fileno(), select.EPOLLIN)
connections[connection.fileno()] = connection
requests[connection.fileno()] = b''
responses[connection.fileno()] = response
elif event & select.EPOLLIN:
requests[fileno] += connections[fileno].recv(1024)
if EOL1 in requests[fileno] or EOL2 in requests[fileno]:
epoll.modify(fileno, select.EPOLLOUT)
print('-'*40 + '\n' + requests[fileno].decode()[:-2])
elif event & select.EPOLLOUT:
byteswritten = connections[fileno].send(responses[fileno])
responses[fileno] = responses[fileno][byteswritten:]
if len(responses[fileno]) == 0:
epoll.modify(fileno, 0)
connections[fileno].shutdown(socket.SHUT_RDWR)
elif event & select.EPOLLHUP:
epoll.unregister(fileno)
connections[fileno].close()
del connections[fileno]
finally:
epoll.unregister(serversocket.fileno())
epoll.close()
serversocket.close()
三、selectors
python">#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Glen
import selectors
import socket
sel = selectors.DefaultSelector() # 还有PollSelector, EpollSelector 等,DefaultSelector它自动选择为当前环境中最有效的Selector
def accept(sock, mask):
conn, addr = sock.accept()
print("accept:", conn, addr)
conn.setblocking(False)
sel.register(fileobj=conn, events=selectors.EVENT_READ, data=read)
def read(conn, mask):
try:
data = conn.recv(1024)
if data:
print("data", conn)
conn.send(data)
else:
print("closing", conn)
sel.unregister(conn) # 注销一个注册的文件对象,返回一个SelectKey对象
conn.close()
except Exception as e:
sel.unregister(conn)
conn.close()
print(e)
sock = socket.socket()
sock.bind(("0.0.0.0", 9999))
sock.listen(10)
sock.setblocking(False)
sel.register(fileobj=sock, events=selectors.EVENT_READ, data=accept)
"""
作用:注册一个文件对象。
参数:fileobj——即可以是fd 也可以是一个拥有fileno()方法的对象;
events 即event Mask 常量:EVENT_READ:表示可读的:它的值其实是1;EVENT_WRITE:表示可写的:它的值其实是2;
data:回调函数
返回一个 SelectorKey类,包含一下四个:
fileobj:表示已经注册的文件对象;
fd:表示文件对象的描述符,是一个整数,它是文件对象的 fileno()方法的返回值;
events
data
"""
while True:
events = sel.select() # 用于选择满足我们监听的event的文件对象
# sel.get_key() # 返回注册文件对象 SelectorKey类的实例
for key, mask in events:
callback = key.data # 表示注册一个文件对象时邦定的data,这里sock绑定的accept函数,conn绑定的是read函数
callback(key.fileobj, mask) # 调用注册时的回调函数
四、IO多路复用ftp
需求:
- 实现文件上传及下载功能
- 支持多连接并发传文件
- 使用select or selectors
python">#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Glen
import selectors
import socket
import os
import time
class FtpServer(socket.socket):
def __init__(self, host, port):
super(FtpServer, self).__init__()
self.host = host
self.port = port
self.file_obj = {}
self.setblocking(False)
self.sel = selectors.DefaultSelector()
self.get_file_size = {}
def ftp_server_start(self):
"""启动ftp_server 交给ftp_accept处理"""
self.bind((self.host, self.port))
self.listen(10)
self.sel.register(fileobj=self, events=selectors.EVENT_READ, data=self.ftp_server_accept)
def ftp_server_accept(self, **kwargs):
"""建立连接 然后注册交给ftp_server_read进行处理"""
conn, addr = self.accept()
conn.setblocking(False)
self.sel.register(fileobj=conn, events=selectors.EVENT_READ, data=self.ftp_server_read)
def ftp_server_read(self, **kwargs):
"""接收client的数据, 然后判断需要进行的操作"""
conn = kwargs["conn"]
try:
data = conn.recv(1024).decode("utf8")
if data:
if data.startswith("get"):
"""接收到get请求, 得到文件名、文件大小,写入字典,修改注册事件,交给ftp_server_send_file处理"""
file_name = data.split()[1]
f = open(file_name, "rb")
file_size = os.stat(file_name).st_size
conn.send(str(file_size).encode("utf8"))
self.file_obj.update({conn: {"file_stream": f, "file_size": file_size}}) # 保存文件信息
self.sel.modify(fileobj=conn, events=selectors.EVENT_WRITE, data=self.ftp_server_send_file)
elif data.startswith("put"):
"""接收到put请求,修改事件,给ftp_server_receive_file处理"""
file_name = data.split()[1]
file_size = data.split()[2]
if os.path.exists(file_name):
file_name = "new" + file_name
f = open(file_name, "wb")
self.get_file_size[conn] = 0 # 为了计算接收到的文件大小而设置的一个变量
self.file_obj.update({conn: {"file_stream": f, "file_size": file_size}}) # 将文件信息保存到字典,方便ftp_server_receive_file获取
self.sel.modify(fileobj=conn, events=selectors.EVENT_READ, data=self.ftp_server_receive_file) # 修改事件状态
else:
conn.send(b"command error")
else:
self.sel.unregister(conn)
conn.close()
except ConnectionResetError as e:
print(e)
self.sel.unregister(conn)
conn.close()
def ftp_server_send_file(self, **kwargs):
"""发送文件,每次发送8k,selector一直循环发送,知道发送完毕,交给read处理"""
conn = kwargs["conn"]
try:
f = self.file_obj[conn]["file_stream"]
file_size = self.file_obj[conn]["file_size"]
data = f.read(8192)
conn.send(data)
pro = f.tell()
time.sleep(0.1)
if pro == file_size:
self.sel.unregister(conn)
self.sel.register(fileobj=conn, events=selectors.EVENT_READ, data=self.ftp_server_read)
f.close()
except ConnectionResetError as e:
self.sel.unregister(conn)
conn.close()
print(e)
def ftp_server_receive_file(self, **kwargs):
conn = kwargs["conn"]
try:
f = self.file_obj[conn]["file_stream"] # 因为该函数需要重复调用请求,f只能在接收命令的时候保存到self.fileobj
file_size = int(self.file_obj[conn]["file_size"])
block_size = 8192
data = conn.recv(block_size) # 由于是非阻塞的,不能while循环接收,让selector循环接收
self.get_file_size[conn] += len(data)
f.write(data)
print(self.get_file_size[conn])
if file_size - self.get_file_size[conn] < block_size: # 最后一次接收
block_size = file_size - self.get_file_size[conn]
data = conn.recv(block_size)
self.get_file_size[conn] += len(data)
f.write(data)
f.close()
self.sel.unregister(conn)
self.sel.register(conn, selectors.EVENT_READ, self.ftp_server_read)
print(self.get_file_size[conn])
del self.get_file_size[conn]
except ConnectionResetError as e:
print(e)
self.sel.unregister(conn)
conn.close()
if __name__ == '__main__':
ftp_server = FtpServer("0.0.0.0", 9999)
ftp_server.ftp_server_start()
while True:
events = ftp_server.sel.select()
for key, mask in events:
callback = key.data
callback(conn=key.fileobj)
python">#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Glen
import socket
import os
import time
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(("localhost", 9999))
while True:
msg = input(">>")
if msg.startswith("get"):
client.send(msg.encode("utf8"))
file_name = msg.split()[1]
if os.path.exists(file_name):
file_name = str(os.getpid()) + file_name
file_size = int(client.recv(1024).decode("utf8"))
f = open(file_name + ".avi", "wb")
get_file_size = 0
block_size = 1024
while get_file_size < file_size:
if file_size - get_file_size < block_size:
block_size = file_size - get_file_size
data = client.recv(block_size)
f.write(data)
get_file_size += len(data)
print(get_file_size)
else:
f.close()
elif msg.startswith("put"):
file_name = msg.split()[1]
file_size = os.path.getsize(file_name)
msg = "put {name} {size}".format(name=file_name, size=file_size)
client.send(msg.encode("utf8"))
print(msg)
with open(file_name, "rb") as f:
for block in f:
time.sleep(0.001)
client.sendall(block)
print(file_name, "send done")
elif msg == "":
continue
else:
client.send(msg.encode("utf8"))
data = client.recv(1024)
print(data.decode("utf8"))


